Tutorial: Writing a JSON Parser (Rust) - Part 2/2
Learn the fundamentals of parsing by building a JSON parser from scratch
This is part 2 of 2, part 1 can be found here.
The source code is available at: https://github.com/davimiku/json_parser
Introduction
In the Part 1, we parsed the String input to a sequence of Tokens. In this part, we'll parse the tokens into the final JSON Value.
Getting Started
Create a new file named parse.rs, which is where the parsing of tokens will be implemented, and add the shell of the parse_tokens function. We'll also define the enum for the possible parsing errors.
// parse.rs
fn parse_tokens(tokens: Vec<Token>, index: &mut usize) -> Result<Value, TokenParseError> {
todo!()
}
#[derive(Debug, PartialEq)]
enum TokenParseError {}
This function uses the same kind of signature as our previous work, it borrows the tokens and produce s either a JSON value or an error.
The way that we're going to parse these tokens is a straight-forward translation of the diagrams on json.org, keep these diagrams handy.
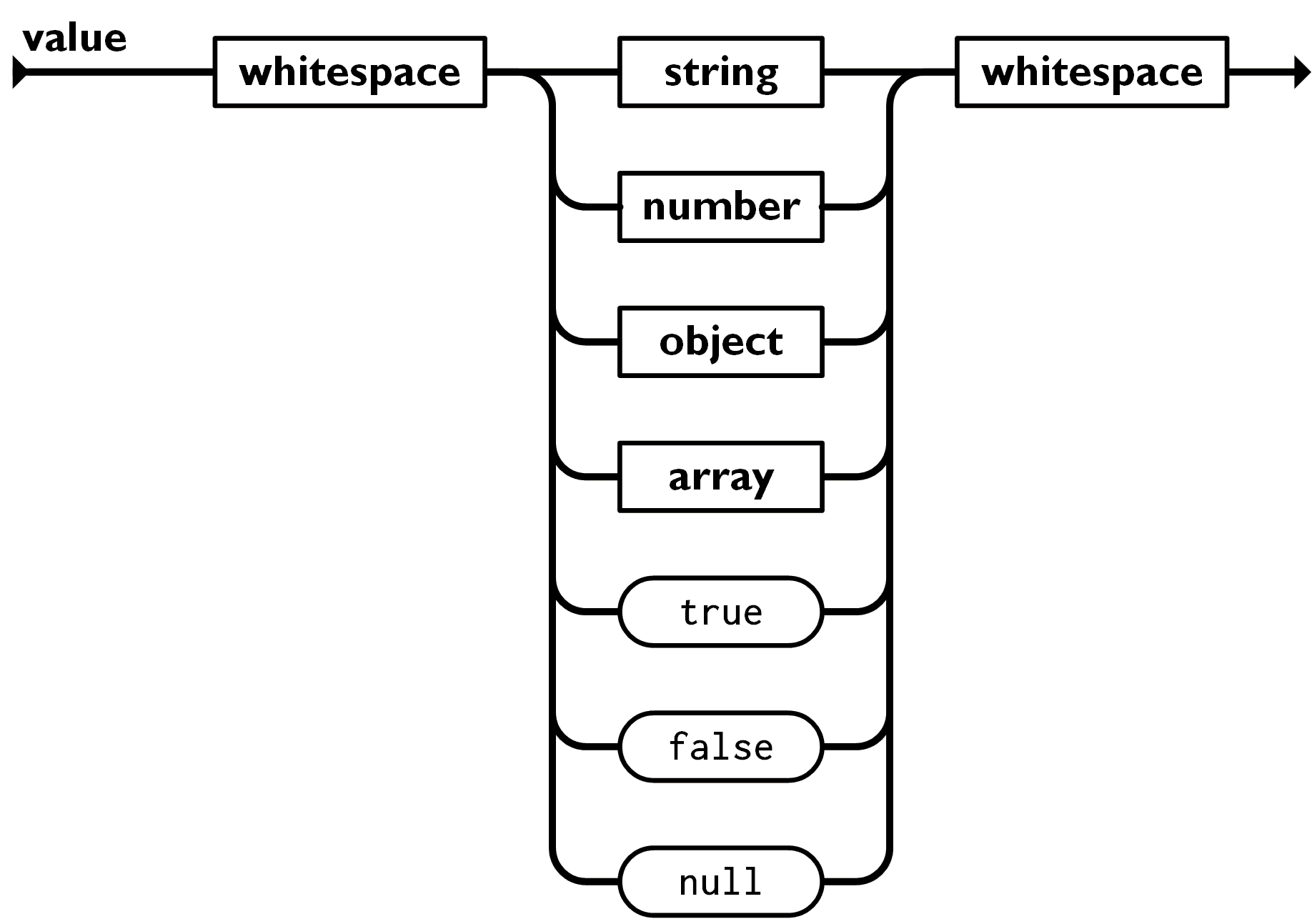
This diagram has a branch with seven possibilities, so our code will do the same:
// parse.rs
fn parse_tokens(tokens: Vec<Token>, index: &mut usize) -> Result<Value, TokenParseError> {
let token = &tokens[*index];
match token {
Token::Null => todo!(),
Token::False => todo!(),
Token::True => todo!(),
Token::Number(number) => todo!(),
Token::String(string) => todo!(),
Token::LeftBracket => todo!(),
Token::LeftBrace => todo!(),
_ => todo!(),
}
}
The seven arms of the match represent the seven possibilities, and the wildcard case at the end will be a parsing error, once we implement that.
Reminder: the (lowercase) number and string in the code above are new variables that are defined for their match arm only, and represent the inner values of the Token::Number and Token::String variants, respectively.
Check the Pattern Matching chapter of the Rust book for more explanation.
Matching Literals
The easiest match arms to start with are the literals.
// parse.rs
fn parse_tokens(tokens: Vec<Token>, index: &mut usize) -> Result<Value, TokenParseError> {
let token = &tokens[*index];
match token {
Token::Null => Ok(Value::Null),
Token::False => Ok(Value::Boolean(false)),
Token::True => Ok(Value::Boolean(true)),
Token::Number(number) => todo!(),
Token::String(string) => todo!(),
Token::LeftBracket => todo!(),
Token::LeftBrace => todo!(),
_ => todo!(),
}
}
The Null, False, and True variants of the Value enum have direct equivalents to the Token enum, so we can immediately create that value without further processing.
Reminder: the Ok(...) part creates a Result value that is the Ok variant.
Notice that we didn't have to use the full path, i.e. Result::Ok(...) to create the variant, whereas we do have to use the full path in Value::Boolean(...). This is due to how Rust imports the Result type automatically into each file. Imagine every file has this at the top:
use std::result::Result;
use std::result::Result::{Ok, Err};
This automatic import allows you to use the Result type, and both its variants Ok and Err directly. These automatic imports are called the prelude.
Importing the individual enum variants can be helpful to reduce verbosity, but be careful to not cause confusing name shadowing. For example, if you imported the individual variants of our Value enum, the Value::String variant would shadow the regular String type. This is legal, but would create more confusing code.
Tests
In the previous article, testing was introduced, which can be a great development tool to ensure that you're on track. We can do the same thing here:
// at the bottom of parse.rs
#[cfg(test)]
mod tests {
use crate::tokenize::Token;
use crate::value::Value;
use super::parse_tokens;
#[test]
fn parses_null() {
let input = vec![Token::Null];
let expected = Value::Null;
let actual = parse_tokens(&input, &mut 0).unwrap();
assert_eq!(actual, expected);
}
}
Feel free to add similar tests for parsing Token::False and Token::True as well.
There's a fairly common practice to introduce a helper function that does any sort of boilerplate data transformation and the assertions for the tests. In this case, there's barely any boilerplate to save but just for the sake of demonstration:
// inside of `mod tests`, among the other tests
// note this function does not have the `#[test]` annotation
fn check(input: Vec<Token>, expected: Value) {
let actual = parse_tokens(&input, &mut 0).unwrap();
assert_eq!(actual, expected);
}
#[test]
fn parses_null() {
let input = vec![Token::Null];
let expected = Value::Null;
check(input, expected);
}
This only saves a single line in each test which may be insignificant (depending on the number of tests), and it adds another moving part, which is something to balance. On the other hand, if you changed the signature of parse_tokens, you'd only need to update a single place in the tests rather than every test.
Later we'll add tests for invalid tokens, which might use a different helper function check_error instead.
It's a trade-off, and the same intuition for whether or not to extract common code into a separate function applies here.
Numbers
The next easiest variant to translate from tokens to JSON value is number.
// parse.rs
fn parse_tokens(tokens: Vec<Token>, index: &mut usize) -> Result<Value, TokenParseError> {
let token = &tokens[*index];
match token {
// ...snip...
Token::Number(number) => Ok(Value::Number(*number)),
// ...snip...
}
}
Reminder from the previous article:
It was hinted that we didn't correctly tokenize JSON numbers, we don't handle the JSON number grammar related to scientific notation, i.e. numbers that look like 6.022e23.
We also fail-fast in the tokenizer on inputs that can't be represented by a 64-bit floating point number (f64). This is valid behavior but not all JSON parsers work like this. Check out the Appendix section at the end of the article for more discussion on JSON numbers.
Feel free to add a test here as well, it should be similar to the existing tests for Null/False/True.
Strings
Parsing the String token should be just as easy... or will it?
Recall that in Part 1, we didn't process escape sequences during tokenization and decided to process those when parsing the token. It's time!
First, we'll create a separate function to handle this, it would be too much code to put in the main match branches:
fn parse_string(s: &str) -> Result<Value, TokenParseError> {
todo!()
}
New Concept: &str
In the previous article, there was a remark that instead of borrowing a Vector using &Vec<T>, it was more idiomatic to use a slice, which would be written like &[T].
Similarly for strings, rather than borrowing a String with &String, it's more idiomatic to use a string slice, which is written as &str.
The difference is subtle and important in general, for a better explanation, please reference the String chapter of the Rust book.
New Concept: type aliases
Now that two different functions both return Result<Value, TokenParseError>, you might decide that it's cumbersome to write this full type out each time. A type alias can be defined like this:
type ParseResult = Result<Value, TokenParseError>;
Then this alias can be used in the two functions that we currently have:
pub fn parse_tokens(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
/// ...snip...
}
fn parse_string(s: &str) -> ParseResult {
/// ...snip...
}
Whether to alias a type or not is a matter of taste, and is a similar kind of question as whether to extract a variable or not. This is something that's typically decided on a case-by-case basis.
Escape Sequences
We need to think through how escape sequences work in JSON. Back to the trusty json.org, which lists out the escapes as:
| Sequence | Description | Unicode Value |
|---|---|---|
\" |
quotation mark | U+0022 |
\\ |
reverse solidus | U+005C |
\b |
backspace | U+0008 |
\f |
form feed | U+000C |
\n |
line feed | U+000A |
\r |
carriage return | U+000D |
\t |
tab | U+0009 |
\uXXXX |
(variable) | U+XXXX |
Knowledge Check
What does the specification say about JSON strings that use a backslash to "escape" a letter that doesn't need to be escaped?
"mind your \p and \q"
The curious case of the solidus
RFC 8259 specifically lists the solidus (also known as "forward slash") in the grammar for escaping characters. However, earlier in that section it clearly lists that the characters that MUST be escaped are quotation mark, reverse solidus, and control characters (U+0000 through U+001F). The solidus can be escaped, in the same way that "p" and "q" can be escaped, as in the example above.
In any case, when parsing if we see \/, \p, or \q, we would basically ignore the backslash and just store /, p, or q (respectively). This goes for any character not listed in the table above, which is why I did not list the solidus there.
What we're going to do is first create an empty String, which will be our "processed" or "unescaped" string, this represents the final parsed value for that string. Then, we'll walk through the Token string character-by-character and if we hit a \ (Reverse Solidus), we'll copy over all the characters so far, process the escape sequence, and then continue.
First, let's call the new function in the main match arms:
// parse.rs
fn parse_tokens(tokens: Vec<Token>, index: &mut usize) -> Result<Value, TokenParseError> {
let token = &tokens[*index];
match token {
// ...snip...
Token::String(string) => parse_string(string),
// ...snip...
}
}
Let's think through how we want to create the processed/unescaped string:
- Create a new (empty) String that will hold the unescaped characters
- Create mutable state to track whether we are in "escape mode" or not
- Walk through the chars of the Token string
- If we are in "escape mode", process the escape sequence, for example with
tpush a Horizontal Tab character into the output. Turn off "escape mode" afterwards - Otherwise if the char is
\then turn on "escape mode" - Otherwise just push the char into the output
- If we are in "escape mode", process the escape sequence, for example with
Let's see the code! First, by prototyping by leaving out the unescaping part for now:
fn parse_string(input: &str) -> ParseResult {
// Create a new string to hold the processed/unescaped characters
let mut output = String::new();
let mut is_escaping = false;
let mut chars = input.chars();
while let Some(next_char) = chars.next() {
if is_escaping {
todo!("implement")
is_escaping = false;
} else if next_char == '\\' {
is_escaping = true;
} else {
output.push(next_char);
}
}
Ok(Value::String(output))
}
New Concept: iterators
The value returned by input.chars() is an iterator, in this case an iterator of char. An iterator is a type that continuously produces the next item of a sequence. To get the next item, the next() function is called which produces an Option<char>, which is Some(char) if there is a next value, or None if there is not.
New Concept: while let
The while let syntax here checks the value of the right-hand side of the assignment (chars.next()) and continues the loop if it is Some or ends the loop if it is None. When the value is some, it grabs the char value that's inside and assigns that to a variable named next_char.
We could have set up this iteration using the loop keyword and manually calling the .next() function ourselves, matching on the value and breaking if a None value is encountered. Using the while let saves a bit of code, it is "syntax sugar".
Efficiency/Performance
The implementation above isn't the most efficient, because the output string will re-allocate many times as new data is pushed into it, depending on the size of the string. Instead of initializing it with String::new(), we could use String::with_capacity(input.len()) to give it an up-front allocation. It will never need to re-allocate because the unescaped string will always be equal or smaller than the escaped string (ex. \t is 2 bytes escaped and 1 byte unescaped, so the unescaped is never larger).
Another idea is instead of pushing to the output string character by character, which is a lot of small copies, it would walk through the input string and increment index counters (start and end). If it saw a backslash, copy a slice of everything so far to the output string, process the escape, then update the start/end counters and continue. At the end, if there's anything left to copy, do a final slice copy using the start/end counters.
The assumption is that most strings in JSON don't contain any escape sequences, so this would end up with only a single copy at the end in the common case. Even in strings with escape sequences, it reduces the total number of copies needed.
We can add a test to check that strings without escape sequences are copied over as-is.
// inside of `mod tests`, among the other tests
#[test]
fn parses_string_no_escapes() {
let input = vec![Token::String("hello world".into())];
let expected = Value::String("hello world".into());
check(input, expected);
}
This should work fine for non-ASCII as well.
// inside of `mod tests`, among the other tests
#[test]
fn parses_string_non_ascii() {
let input = vec![Token::string("olá_こんにちは_नमस्ते_привіт")];
let expected = Value::String(String::from("olá_こんにちは_नमस्ते_привіт"));
check(input, expected);
}
#[test]
fn parses_string_with_emoji() {
let input = vec![Token::string("hello 💩 world")];
let expected = Value::String(String::from("hello 💩 world"));
check(input, expected);
}
While we're at it, we can add tests that will fail until we implement the unescaping.
// inside of `mod tests`, among the other tests
#[test]
fn parses_string_unescape_backslash() {
let input = vec![Token::String(r#"hello\\world"#.into())];
let expected = Value::String(r#"hello\world"#.into());
check(input, expected);
}
// ...snip...
// replace the entire `while let` block with this:
while let Some(next_char) = chars.next() {
if is_escaping {
match next_char {
'"' => output.push('"'),
'\\' => output.push('\\'),
// `\b` (backspace) is a valid escape in JSON, but not Rust
'b' => output.push('\u{8}'),
// `\f` (formfeed) is a valid escape in JSON, but not Rust
'f' => output.push('\u{12}'),
'n' => output.push('\n'),
'r' => output.push('\r'),
't' => output.push('\t'),
'u' => todo!("Implement hex code escapes"),
// any other character *may* be escaped, ex. `\q` just push that letter `q`
_ => output.push(next_char),
}
is_escaping = false;
} else if ch == '\\' {
is_escaping = true;
} else {
output.push(next_char);
}
}
// ...snip...
Note that Rust strings do not have a special syntax for the Backspace and Form Feed characters, so we use the general Unicode escape syntax. Also note that the Rust syntax for Unicode escape is not the same as the JSON syntax for that.
Unicode Escapes
Processing the unicode escape (the one starting with \u) is a bit tricky, but thankfully we can use a bunch of helper functions from the Rust standard library.
Reviewing the JSON syntax for unicode escape:
\uXXXX -- where X is a hexadecimal digit (0-9 or A-F or a-f)
unicode escape sequences in other languages
Anywhere with X, assume this to mean a hexadecimal (base-16) digit.
JavaScript's escape syntax is the same as JSON (JSON is based on JavaScript):
-- general format
\uXXXX
-- example for ¥ (U+00A5)
\u00A5
-- example for 🌼 (U+1F33C)
🌼
The 🌼 has to be broken up into two parts (surrogate pair) because only 4 hexadecimal digits are available. 4 digits = (16^4) = 65,536 possible values but there are more than 65k possible characters out there in the world. The current v15.0 specification of Unicode has 149,186 characters.
We saw Rust's version earlier for processing the Form Feed and Backspace:
-- general format
\u{X} -- where X is 1-6 hexadecimal characters
-- example for ¥ (U+00A5)
\u{A5}
-- example for 🌼 (U+1F33C)
\u{1F33C}
This allows up to 6 hexadecimal digits, which is (16^6) or 16,777,216 total. That has capacity for about 110x the amount of characters today, so it may run out at some point far in the future, but not something to worry about for a while. If there are less than 6 digits, leading zeros are not required.
Java is similar to JSON (presumably JavaScript's syntax was based on Java), but you can actually have as many u as you want and it's the same:
-- general format
\uXXXX
-- you can have as many 'u' as you want and its the same
\uuuuuuuuuuuuuuuuuuuuuXXXX
-- example for ¥ (U+00A5)
\u00A5
-- example for 🌼 (U+1F33C)
�\uuuuuuuuuuDF3C
I'm honestly not sure of the usecase for infinite u characters but it's likely not common.
Python (3) has two different representations:
\uXXXX -- up to (16^4) = 65,536
\UXXXXXXXX -- up to (16^8) = 4,294,967,296
-- example for ¥ (U+00A5)
\u00A5
-- example for 🌼 (U+1F33C)
\U0001F33C
-- surrogate pairs 🌼 is *not* a valid escape in a Python (3) string literal
Note that we actually aren't going to handle surrogate pairs in this implementation. See the Appendix section for more details.
What we want to do is:
- Initialize a sum variable (integer, start at zero)
- Walk forwards by 4 characters
- Convert the read character into a radix-16 digit (A=10, B=11, C=12, etc.)
- Add it to the sum
- Convert the sum from an integer (
u32) to achar. Note that this can fail if the integer is larger than the maximum valid code point (U+10FFFF) - Push this
charto the current output
// ...snip...
'u' => {
let mut sum = 0;
for i in 0..4 {
let next_char = chars.next().ok_or(TokenParseError::UnfinishedEscape)?;
let digit = next_char
.to_digit(16)
.ok_or(TokenParseError::InvalidHexValue)?;
sum += (16u32).pow(3 - i) * digit;
}
let unescaped_char =
char::from_u32(sum).ok_or(TokenParseError::InvalidCodePointValue)?;
output.push(unescaped_char);
}
// ...snip...
// add these new variants to the enum
pub enum TokenParseError {
// ...snip...
/// An escape sequence was started without 4 hexadecimal digits afterwards
UnfinishedEscape,
/// A character in an escape sequence was not valid hexadecimal
InvalidHexValue,
/// Invalid unicode value
InvalidCodePointValue,
}
New Concept: integer literal suffixes
The 16u32 is the integer 16 with a u32 suffix which says which kind of integer it is (in Rust there are a bunch of kinds of integers, so just writing 16 can be ambiguous).
The pow() function therefore takes a u32 as its first parameter. Integers need to be surrounded by parentheses when using "dot syntax" (method call syntax) to call functions because otherwise the dot might be parsed as a decimal point.
Arrays
Arrays! The first of two more "complex" types, but the code is actually not bad.
Looking back to our main parse_tokens function, we can add the case for arrays, which starts when a LeftBracket token is encountered.
pub fn parse_tokens(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
let token = &tokens[*index];
match token {
// ...snip...
Token::LeftBracket => parse_array(tokens, index),
// ...snip...
}
}
The parse_array function receives a reference to the tokens and the current index. Take a moment to think through the implementation of this function. When you're ready, proceed below!
What we'll do is:
- Create an empty
Vecto output all the values that will be parsed from the array - Loop:
- Increment the index by 1 (to consume the
LeftBracket) - Call
parse_tokens(recursively) to get aValue, and push that into our outputVec - Increment the index by 1 to get the next token. If it is a
RightBracket, break the loop. If it is aComma, consume that and continue the loop. Otherwise, it's an error.
- Increment the index by 1 (to consume the
fn parse_array(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
let mut array: Vec<Value> = Vec::new();
loop {
// consume the previous LeftBracket or Comma token
*index += 1;
let value = parse_tokens(tokens, index)?;
array.push(value);
let token = &tokens[*index];
*index += 1;
match token {
Token::Comma => {}
Token::RightBracket => break,
_ => return Err(TokenParseError::ExpectedComma),
}
}
// consume the RightBracket token
*index += 1;
Ok(Value::Array(array))
}
// add this new variant to the enum
pub enum TokenParseError {
// ...snip...
ExpectedComma,
}
Now, adding a test:
// inside of `mod tests`, among the other tests
#[test]
fn parses_array_one_element() {
// [true]
let input = vec![Token::LeftBracket, Token::True, Token::RightBracket];
let expected = Value::Array(vec![Value::Boolean(true)]);
check(input, expected);
}
...and it works? Seems too easy, what about another test, this time with two elements:
// inside of `mod tests`, among the other tests
#[test]
fn parses_array_two_elements() {
// [null, 16]
let input = vec![
Token::LeftBracket,
Token::Null,
Token::Comma,
Token::Number(16.0),
Token::RightBracket,
];
let expected = Value::Array(vec![Value::Null, Value::Number(16.0)]);
check(input, expected);
}
OK that works too, what about this?
// inside of `mod tests`, among the other tests
#[test]
fn parses_empty_array() {
// []
let input = vec![Token::LeftBracket, Token::RightBracket];
let expected = Value::Array(vec![]);
check(input, expected);
}
Ah here we go, this one failed. Back to our loop, we need to check for a RightBracket at the top of the loop and break if so.
// inside of `parse_array`
loop {
// consume the previous LeftBracket or Comma token
*index += 1;
if tokens[*index] == Token::RightBracket {
break;
}
// ...snip...
}
What about nested arrays? We should be able to handle that:
// inside of `mod tests`, among the other tests
#[test]
fn parses_nested_array() {
// [null, [null]]
let input = vec![
Token::LeftBracket,
Token::Null,
Token::Comma,
Token::LeftBracket,
Token::Null,
Token::RightBracket,
Token::RightBracket,
];
let expected = Value::Array(vec![Value::Null, Value::Array(vec![Value::Null])]);
check(input, expected);
}
...and panic. oof.
failures:
---- parse::tests::parses_nested_array stdout ----
thread 'parse::tests::parses_nested_array' panicked at src\parse.rs:70:28:
index out of bounds: the len is 7 but the index is 7
ugh. Another off-by-one error. This is the grungy side of an imperative, state-based style of parser with a manually incremented index. In this case, we've incremented the index one too many times.
There are multiple ways this could be solved - all of them involve juggling where the index is incremented (remove it from here, add it to over there). If you have your own idea, feel free to break from the tutorial here!
One way to solve it is that for the simple documents (Null, True, False, String, Number) we didn't bother to increment the index in parse_tokens because up until now, these documents only had a single token and we didn't care. This put the burden on parse_array to increment for these simple tokens, which worked until we had a nested array, and then we incremented too much.
Up in the parse_tokens function we can go ahead and increment the index for the simple tokens. That way the parse_array (and parse_object) functions only have to worry about their own tokens.
pub fn parse_tokens(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
let token = &tokens[*index];
if matches!(
token,
Token::Null | Token::False | Token::True | Token::Number(_) | Token::String(_)
) {
*index += 1
}
match token {
// ...snip...
}
}
Was this detour an honest mistake by the author or a contrived way to introduce a new concept? You be the judge.
New Concept: declarative macros
The matches! with the exclamation mark that looks kind of like a function call is a macro, specifically a declarative macro.
Macros are written in a language that mostly resembles Rust, and the purpose of macros is to generate Rust code at compile time. In your code editor, you should be able to "Go To Definition" (usually F12) to see how the matches! macro is written. Macros are great for reducing repetitive code or improving local readability.
However, as with anything, there is a balance. Too much macro-generated code can make it harder to read rather than easier, and in some cases can have an impact on compile time.
Now that the simple tokens increment the index for themselves, we can remove the 2nd increment from the loop in parse_array.
loop {
// ...snip...
let token = &tokens[*index];
// *index += 1; // <-- REMOVE THIS
match token {
Token::Comma => {}
Token::RightBracket => break,
_ => return Err(TokenParseError::ExpectedComma),
}
}
Now, parse_array is responsible for incrementing for the LeftBracket, Comma, and RightBracket, but not responsible for the array values. That makes sense!
Objects
Objects are more complex than Arrays, but are the same idea. Conceptually, Objects can be thought of as an Array where the elements are String-Colon-Value.
pub fn parse_tokens(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
// ...snip...
match token {
// ...snip...
Token::LeftBrace => parse_object(tokens, index),
// ...snip...
}
}
To start implementing parse_object, we'll follow a similar pattern as parse_array:
fn parse_object(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
let mut map = HashMap::new();
loop {
// consume the previous LeftBrace or Comma token
*index += 1;
if tokens[*index] == Token::RightBrace {
break;
}
}
// Consume the RightBrace token
*index += 1;
Ok(Value::Object(map))
}
Learned from our mistakes! We started with handling the "base case" of an empty object this time.
// OK cases
LeftBrace -> RightBrace
LeftBrace -> String -> Colon -> Value -> RightBrace
LeftBrace -> [String -> Colon -> Value] -> Comma -> (repeat [*]) -> RightBrace
If the first token after the LeftBrace isn't a RightBrace, then it needs to be a String (the key of the property).
fn parse_object(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
// ...snip...
loop {
// ...snip...
if let Token::String(s) = &tokens[*index] {
todo!();
} else {
return Err(TokenParseError::ExpectedProperty);
}
}
// ...snip...
}
// add this new variant to the enum
pub enum TokenParseError {
// ...snip...
ExpectedProperty,
}
New Concept: if let
The if let syntax is a way to do control flow when you want to match one pattern specifically. Just like in other pattern matching, the s variable is a new variable being defined if the token matches Token::String. This could also be written as:
match &tokens[*index] {
Token::String(s) => todo!(),
_ => return Err(TokenParseError::ExpectedProperty),
}
In some cases, if let can be more concise. Another thing to consider with readability is intent, the if let syntax shows that one variant than the others, whereas in a match, all the variants are roughly "equal", so to speak.
We returned an error if the next token was not a Token::String, now for the logic if it is. The next tokens needs to be Token::Colon, otherwise there's an error.
fn parse_object(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
// ...snip...
loop {
// ...snip...
if let Token::String(s) = &tokens[*index] {
*index += 1;
if Token::Colon == tokens[*index] {
todo!();
} else {
return Err(TokenParseError::ExpectedColon);
}
} else {
return Err(TokenParseError::ExpectedProperty);
}
}
// ...snip...
}
Knowledge Check
Why not if let this time?
This time we didn't need to get the value "inside" the Token::Colon variant, because there is no value inside. if let is useful for checking for a match and getting the inner value in a single expression.
Now to actually add the value! We already have the String, which will be the key for the entry in the map. We need to clone the String because the Token currently owns it, so we need another copy to store in the Value.
The value for the entry can be any JSON Value, including another Object - so we go to our trusty friend recursion again by calling parse_tokens, just like in the Array.
fn parse_object(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
// ...snip...
loop {
// ...snip...
if let Token::String(s) = &tokens[*index] {
*index += 1;
if Token::Colon == tokens[*index] {
*index += 1;
let key = s.clone();
let value = parse_tokens(tokens, index)?;
map.insert(key, value);
} else {
return Err(TokenParseError::ExpectedColon);
}
} else {
return Err(TokenParseError::ExpectedProperty);
}
}
// ...snip...
}
Optional, kind of: do Object keys need to be unescaped?
TL;DR - Yes - but if you want to just get to the end of the tutorial, you can skip this part.
RFC 8259 describes the grammar as:
object = begin-object [ member *( value-separator member ) ]
end-object
member = string name-separator value
Where the "string" part is defined in a section further below that contains all the escape-y stuff that we dealt with for strings.
We've already done all that work, just needs a little refactor to make it available. Split out the unescaping part from parse_string like this:
fn parse_string(input: &str) -> ParseResult {
let unescaped = unescape_string(input)?;
Ok(Value::String(unescaped))
}
fn unescape_string(input: &str) -> Result<String, TokenParseError> {
// Create a new string to hold the processed/unescaped characters
let mut output = String::new();
let mut is_escaping = false;
for ch in input.chars() {
// ...snip...
}
Ok(output)
}
Then in parse_object we can replace the let key = s.clone() with let key = unescape_string(s)?.
Almost done - after a key/value pair comes either a Comma or a RightBrace.
fn parse_object(tokens: &Vec<Token>, index: &mut usize) -> ParseResult {
// ...snip...
loop {
// ...snip...
if let Token::String(s) = &tokens[*index] {
// ...snip...
match &tokens[*index] {
Token::Comma => {}
Token::RightBrace => break,
_ => return Err(TokenParseError::ExpectedComma),
}
} else {
// ...snip...
}
}
// ...snip...
}
Add tests! This will be left as "an exercise for the reader".
Putting it all together!
// suggestion: put this near the top, just below `mod` and `use` statements
pub fn parse(input: String) -> Result<Value, ParseError> {
let tokens = tokenize(input)?;
let value = parse_tokens(&tokens, &mut 0)?;
Ok(value)
}
// suggestion: put this below the definition of `Value`
#[derive(Debug, PartialEq)]
pub enum ParseError {
TokenizeError(TokenizeError),
ParseError(TokenParseError),
}
impl From<TokenParseError> for ParseError {
fn from(err: TokenParseError) -> Self {
Self::ParseError(err)
}
}
impl From<TokenizeError> for ParseError {
fn from(err: TokenizeError) -> Self {
Self::TokenizeError(err)
}
}
The suggestion to put parse at the top of the lib.rs is because this is our main exported item. Anyone using our library will basically be focused on this. The function also exposes our types Value and ParseError, in that order, so I suggest defining those immediately after (in that order). Basically, public/exported items at the top and everything else below.
New Concept: From trait
Many times throughout this tutorial, we have used #[derive(...)] to automatically derive traits for the types that we have defined.
In this case, we are directly implementing the From trait. This trait represents converting from one type of data to another where that conversion cannot fail (since there is no Result in the function signature, it cannot fail). In order to successfully implement the From trait, we must implement a from function which has a signature T -> Self.
The ? operator doesn't just propagate an error value, it also uses any From implementations as needed. This is how the error from tokenize and the error from parse_tokens are both able to convert to the top-level ParseError.
Consider writing more tests! Now that the public/exported parse function is written, you can write tests against this public function.
Should you delete the existing tests for the internal tokenize and parse_tokens functions? Why or why not?
Appendix and Further Exercises
A semi-random list of items to improve the current implementation of parsing or items for further research.
Better Error Handling
The current implementation actually panics on malformed input, rather than cleanly returning an error. For example, run tests with an input of [true or {"key":"value" (unclosed brackets/braces). This is because in several places we increment the index variable and assume there is a token rather than checking.
As a challenge, handle these kinds of input with an error. Consider abstracting out the idea of "get the next token" such that it handles errors instead of panics.
Using &str instead of String
In part 1, the tokenize() function takes a String argument. At the time, the concept of a "string slice" (&str) had not been explained yet in the tutorial, so String was a simpler way to get started.
However, there are actually downsides of using String - this forces the user of our library to give ownership of their string to our library, when this really isn't necessary. Our library doesn't need ownership of the input string, we only need a read-only borrow (i.e. a shared borrow), and this is exactly what &str is for.
Consider refactoring the tokenize function and the top-level parse function to accept a &str instead of String. Change all tests as appropriate (this actually removes some boilerplate from the tests too!).
UTF-16 and Surrogate Pairs
The Unicode escape sequence in JSON is uXXXX where each X is a hexadecimal digit. Thus, the total number of code points that can be represented in an escape sequence is 16^4 or 65,536. However, there are many code points with a value higher than that, such as 🌼 (U+1F33C).
These are represented as "surrogate pairs". On their own, each item of the pair are not valid, but together with some math, they can be converted to the code point value.
Surrogates are code points from two special ranges of Unicode values, reserved for use as the leading, and trailing values of paired code units in UTF-16. Leading surrogates, also called high surrogates, are encoded from D800 to DBFF, and trailing surrogates, or low surrogates, from DC00 to DFFF. They are called surrogates, since they do not represent characters directly, but only as a pair.
https://www.unicode.org/faq/utf_bom.html#utf16-1
U+D800 through U+DFFF are permanently reserved for surrogate pairs and must not appear on their own in well-formed UTF-16 (unfortunately, ill-formed UTF-16 exists in the wild and Windows file paths may contain values in this range that are unpaired).
As a challenge, implement unescaping surrogate pairs in the parsing. A test case is that the escaped r#"hello🌼world"# should unescape to "hello🌼world".
Trailing Commas
Does our current implementation allow trailing commas in Array and Object? Is this correct or not?
Does RFC8259 forbid trailing commas? i.e. if a parser correctly handles JSON syntax as defined in RFC8259 and additionally it also handles JSON with trailing commas, is that parser compliant with RFC8259?
As a challenge, implement an error for trailing commas. Does this make the implementation more or less complicated?
Objects with duplicate keys
If the incoming String that we are parsing represents a JSON object, and that JSON object has multiple keys that are the same, what should we do? Do we return an error? Or is it successful and we discard all but one of the duplicated keys? Which one key should remain?
{
"a": 0,
"a": 1,
"a": 2
}
RFC 8259 specifies that the names within a JSON object SHOULD be unique.
An object whose names are all unique is interoperable in the sense that all software implementations receiving that object will agree on the name-value mappings. When the names within an object are not unique, the behavior of software that receives such an object is unpredictable. Many implementations report the last name/value pair only. Other implementations report an error or fail to parse the object, and some implementations report all of the name/value pairs, including duplicates.
What does JavaScript do?
const str = `{"a": 1, "a": 2}`
console.log(JSON.parse(str)) // --> { a: 2 }
It keeps the last name/value pair only, our implementation will do the same.
Interestingly, this non-specified behavior of JSON can lead to vulnerabilities! If one system keeps the first duplicated key and another system keeps the last key, a clever actor could find a way to exploit this. Further reading with examples of parsers that treat duplicate keys differently, and the impact: An Exploration of JSON Interoperability Vulnerabilities
Object Key Ordering
Another interesting question is whether JSON object keys should be kept in the same order that they are in the source document.
{
"c": 0,
"b": 0,
"a": 0
}
Consulting RFC 8259 again:
An object is an unordered collection of zero or more name/value pairs, where a name is a string and a value is a string, number,boolean, null, object, or array.
JSON parsing libraries have been observed to differ as to whether or not they make the ordering of object members visible to calling software. Implementations whose behavior does not depend on member ordering will be interoperable in the sense that they will not be affected by these differences.
Our current implementation stores the JSON Object properties in a HashMap which is unordered, so we can stick with this.
Knowledge Check
What Rust standard library type could we use instead if we wanted to keep the keys ordered?
Numbers with Scientific Notation
JSON numbers are allowed to be written in "scientific notation", such as 6.022e23 which means "6.022 * 10^23".
As a challenge, implement tokenizing and parsing for this kind of number syntax.
Number precision
What are the size limits on a JSON number? 32-bit integer? 64-bit floating point? What happens when numbers are really big or really close to zero?
RFC 8259 says:
This specification allows implementations to set limits on the range and precision of numbers accepted. Since software that implements IEEE 754 binary64 (double precision) numbers [IEEE754] is generally available and widely used, good interoperability can be achieved by implementations that expect no more precision or range than these provide, in the sense that implementations will approximate JSON numbers within the expected precision.
Essentially, the answer is there is no standard for what numbers can be reliably sent and received as JSON. For integers, if the value is between Number.MIN_SAFE_INTEGER and Number.MAX_SAFE_INTEGER, then it's likely to be interoperable with most implementations. However, it would be legal for implementations to be less precise than this, as long as the implementation correctly parsed the grammar of the number syntax, the precision that such number is stored at is not specified.
This specification favors practicality over preciseness. This makes it easy to implement a JSON parser - it can be mostly done in a pair of tutorial articles! - but small inconsistencies like this can unfortunately lead to issues (including vulnerabilities). If the number cannot be represented in the chosen precision, what happens? An error? Silent loss of precision?
If the messages you're sending/receiving require precise behavior with numbers, you have to be really careful that both sides have the same implementation behavior, or JSON may not be the best choice of a data format. Take a look at the JSON parser for the language that you primarily use, what is the documented behavior for numbers?
Text encoding
What encoding should be allowed for JSON documents? UTF-8? Only ASCII? Windows-1252?
Back to RFC 8259:
JSON text exchanged between systems that are not part of a closed ecosystem MUST be encoded using UTF-8
UTF-8 is by far the most common encoding for messages sent on the internet, so this restriction makes a lot of sense. If you have your own servers communicating to each other, it's fine to use an alternative encoding, but public APIs would expect UTF-8.
Our library accepts a String parameter, which is guaranteed to be UTF-8, so we've decided that it's not the responsibility of our library to deal with string encoding. We could have instead accepted a slice of bytes, which would lead to additional design decisions, i.e. do we report and error if it's not UTF-8? Do we try to dynamically detect the encoding and convert it automatically?
Another interesting note from RFC 8259:
Implementations MUST NOT add a byte order mark (U+FEFF) to the beginning of a networked-transmitted JSON text. In the interests of interoperability, implementations that parse JSON texts MAY ignore the presence of a byte order mark rather than treating it as an error.